What VLMs Bring to Quality Control
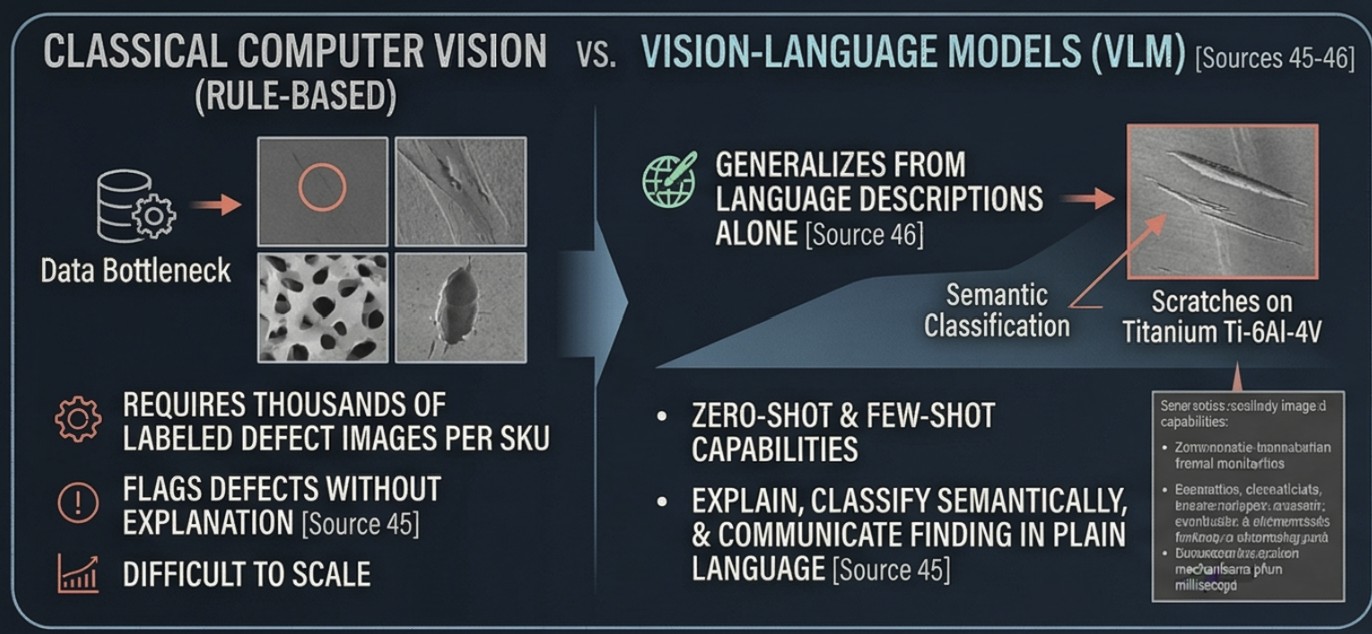
Vision-Language Models (VLMs) represent a paradigm leap beyond classical computer vision: they simultaneously understand images and natural language, enabling a system to not just flag a defect but to explain it, classify it semantically, and communicate the finding in plain language to operators or upstream control systems. Unlike rule-based or single-modal deep learning systems that require thousands of labeled defect images per SKU, VLMs can operate zero-shot or few-shot — meaning they can inspect product types they have never explicitly been trained on, generalizing from language descriptions alone. This directly addresses one of manufacturing's most persistent data bottlenecks: the scarcity of labeled defect examples in real production environments.
The Research Frontier: QA-VLM & Additive Manufacturing
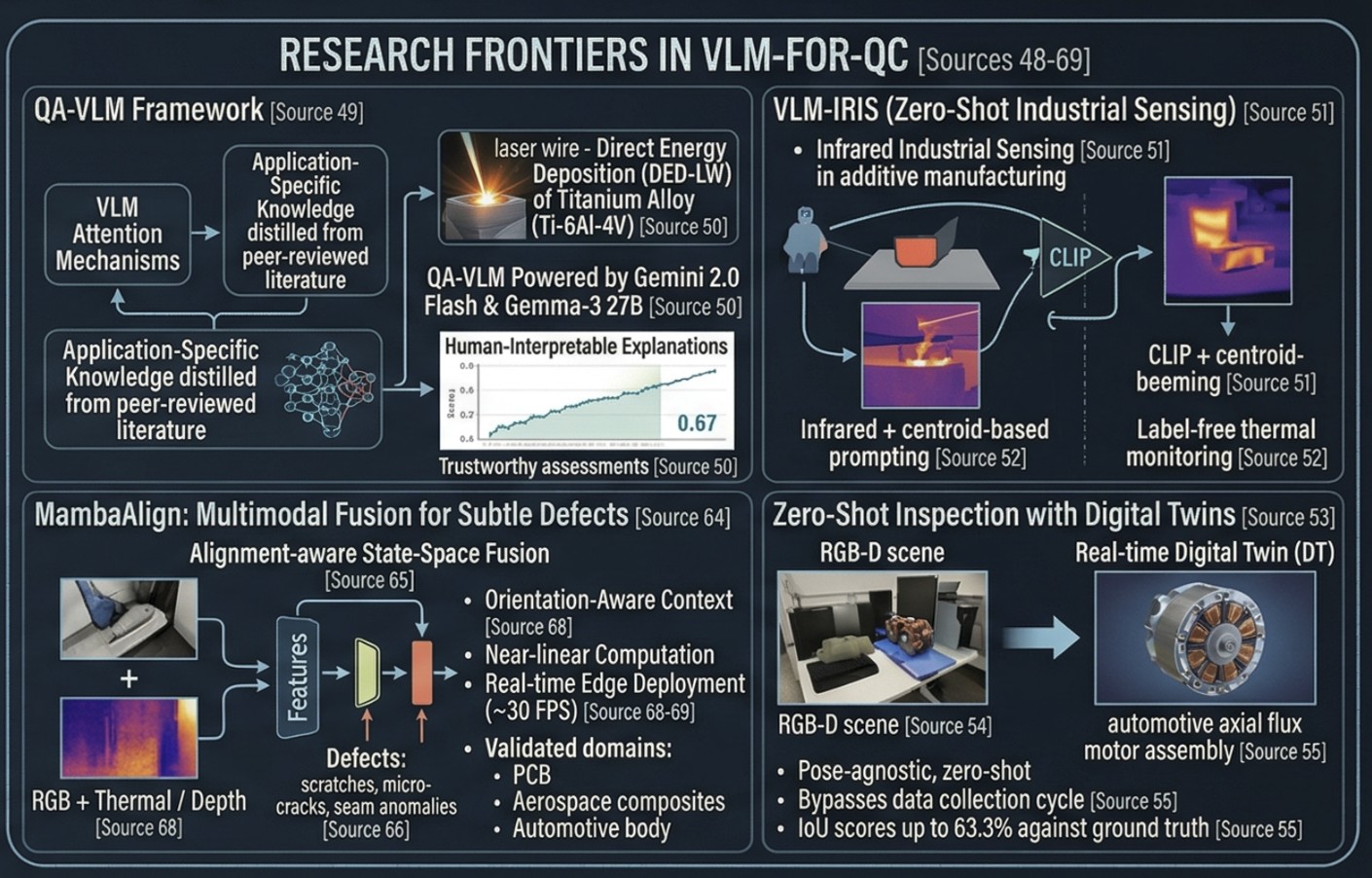
The most technically rigorous VLM-for-QC framework published to date is QA-VLM, a novel architecture that fuses VLM attention mechanisms with application-specific knowledge distilled from peer-reviewed literature — in essence, teaching the model industrial domain expertise rather than relying on general pretrained knowledge. Validated on laser wire Direct Energy Deposition (DED-LW) of titanium alloy (Ti-6Al-4V), QA-VLM powered by Gemini 2.0 Flash and Gemma-3 27B produced quality assessments with validity scores around 0.67, on par with classical ML models — but with the critical addition of human-interpretable explanations, making the system auditable and trustworthy for process engineers.
A parallel framework, VLM-IRIS, applies VLMs to infrared industrial sensing in additive manufacturing using a zero-shot approach. The best configuration combines CLIP with magma preprocessing and centroid-based prompting to achieve strong zero-shot classification accuracy — enabling label-free thermal monitoring without requiring a single labeled training image.
Zero-Shot Inspection with Digital Twins
A major research breakthrough gaining production traction in 2026 is pose-agnostic, zero-shot quality inspection that compares real scenes against real-time Digital Twins (DT) in the RGB-D (color + depth) space. Applied to an automotive axial flux motor assembly use case, this framework achieves IoU scores up to 63.3% against ground truth defect masks under semi-controlled conditions — without any model training on product-specific data. This approach is architecturally significant for engineers: it means any new product variant introduced to the line can be inspected immediately using its CAD/digital twin model as the reference, completely bypassing the data collection and labeling cycle.
Zero-Shot Industrial Anomaly Detection (ZSIAD)
The IJCAI 2025 proceedings introduced a VLM-based Hybrid Explainable Prompt Enhancement framework for ZSIAD — arguably the most sophisticated approach to zero-shot anomaly detection in industrial settings. Key architectural elements:
- A multi-stage prompt generation agent uses Multimodal LLMs (MLLMs) to articulate fine-grained differential descriptions between normal and anomalous states.
- A Visual Fundamental Model (VFM) generates anomaly-related attention prompts for accurate localization of defects with varying sizes and shapes.
- Validated across seven real-world industrial anomaly detection datasets, outperforming prior state-of-the-art methods.
The explainable prompt design means engineers receive not just "defect detected" but a semantic, localized, and reasoned diagnosis — a meaningful step toward trustworthy AI in regulated manufacturing environments.
MambaAlign: Multimodal Fusion for Subtle Defects
Published in February 2026 by researchers at Shibaura Institute of Technology, MambaAlign introduces an alignment-aware state-space fusion framework for multimodal industrial anomaly detection. It is specifically designed to catch thin, oblique, or subtle defects — scratches, micro-cracks, seam anomalies — that elude standard single-sensor models. Key technical properties:
- MambaAlign exchanges semantic guidance between sensors only at high-level feature stages, avoiding the memory explosion of full global attention, making it practical for edge deployment on the production line without a GPU cluster.
Production Deployments: Real Factory Numbers
The gap between research and production is closing rapidly, with some world-class manufacturers already operating at scale:
- Samsung semiconductor fabs: inspect 30,000–50,000 units/day per line at 99.5% defect detection accuracy, up from 85–90% before AI.
- Foxconn: unsupervised learning-based AI visual inspection improved accuracy from 95% → 99% while cutting inspection costs by ≥33%.
- Intel: Intelligent Wafer Vision Inspection catches micron-level defects invisible to humans, saving approximately $2M annually.
- Google Cloud Visual Inspection AI: demonstrated a 10× accuracy improvement over general-purpose ML using 300× fewer labeled images — a landmark result for low-data factory environments.
VLMs Integrated with SAP, PLC, and Shop Floor Systems
SAP Business AI's Anomaly Detection POD Plugin — now live in production deployments — deploys computer vision and deep learning models directly at the edge on the shop floor, integrating AI-powered defect detection into the MES/ERP layer without routing data to the cloud. This architecture is precisely what IIoT practitioners have been building toward: AI quality judgment embedded within the MES-SCADA-PLC integration stack, where flagged defects can trigger automated rejection mechanisms (pneumatic pushers, robotic sorters) in milliseconds via direct PLC signaling.
The Five-Tier AI Quality Architecture in 2026
Modern AI quality control is no longer a single inspection node. The 2026 architecture is a full-spectrum pipeline:
- Automated visual inspection — CNNs and VLMs for surface defects, assembly errors, label/print validation, 100% inline at full production speed.
- Multimodal fusion — correlating vision outputs with PLC sensor data, thermals, and vibration to move from "what failed" to "what caused it".
- Predictive quality — ML models trained on historical process data predicting defect probability before final inspection, enabling proactive parameter adjustment.
- Generative synthetic data — AI-generated defect images to overcome training data scarcity for rare failure modes.
- LLM-powered quality reporting — natural language queries over quality databases, automated shift reports, and deviation summaries for engineers and managers.
Vision AI Market & Deployment Outlook
Over 70% of manufacturers plan to deploy AI-based visual inspection within 18 months, making 2026 the tipping point year for industrial Vision AI adoption at scale. The machine vision market is projected to grow from $20.4B in 2024 to $41.7B by 2030, driven primarily by AI-first inspection systems. In a parallel survey, 41% of manufacturers cite Vision AI as their top automation priority specifically because it directly addresses quality control and "profitless prosperity" — the phenomenon of high revenue masked by hidden scrap and rework costs.
Key Implications for Automation Engineers
- Zero-shot and few-shot VLMs eliminate the data labeling bottleneck — new product variants can be inspected immediately using natural language descriptions or digital twin references.
- Explainability is becoming a hard requirement — QA-VLM and ZSIAD prompt-based frameworks deliver auditable, human-readable defect rationale, critical for regulated industries (aerospace, medical devices, automotive).
- Edge deployment is non-negotiable — MambaAlign, VLM-IRIS, and SAP's edge QC stack all confirm that real-time inference at 30 FPS must happen on the factory floor, not in the cloud.
- VLMs are moving up the control stack — from passive inspection reporters to active participants in closed-loop quality control, directly triggering rejection, escalation, or process correction via PLC/MES integration.
About the Author
Nay Linn Aung is a Senior Automation & Robotics Engineer with 12+ years in PLC, SCADA, collaborative robotics, and AI/ML. Currently pursuing an M.S. in Computer Science (Data Science & AI) at Hood College.